How to remember vocabulary in dozens of languages:
It may seem like something only professors study and useless to the average language learner. But there are secret hacks to be found and unlocked within the hierarchy of how scientists group languages together.
In this article, I'll touch on why it's important to understand the relationships and what some of those relationships are. In the next post we'll use our new-found knowledge to start hacking.

Language Families
Linguists have several methods to determine whether a language is related to another. As language learners we can use these methods as hacks to acquire vocabulary and grammar more effectively than students who are learning in a classroom setting.
First, linguists have a list of words that are most unlikely to be borrowed from other languages which lets them see the true source sounds of the language. These sounds were passed down regularly over time and with each successive generation languages change slightly. If you've ever noticed that your grandparents speak differently, this is a sign that you're witnessing language change. Linguistic theory tells us how language changes over time. In addition we have good records of Latin and Ancient Greek and we can compare all the changes with today's modern languages. Those regular soung changes show up in almost all language families worldwide.
The Roman Empire existed over a long period of time, so there are many stages of Latin that we can track. After the fall of the Roman Empire, communities were spread out over a very large area of land, and individual dialects started to form, eventually changing enough into their own distinct languages. We know that it takes about 1000 years for a language to become distinct.
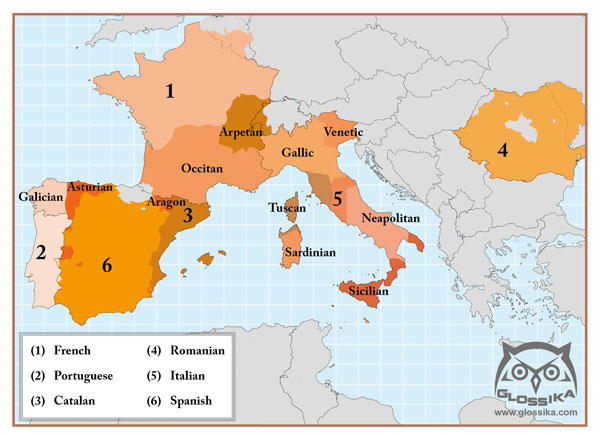
The languages directly descended from Latin include Romanian, Italian, French, Spanish, and Portuguese. However these aren't the true descendants, as these were invented by modern governments to unify everybody within their countries so they can communicate with each other. The true descendants include Sicilian, Tuscan, Venetian, Gascon, Provencal, Galician and many others. The national standard Italian, for example was created based mostly on Tuscan but incorporates elements from other regions. People still speak the regional languages in Italy today and only use the national language as a spoken register for official purposes or for speaking wih outsiders. This is actually quite true in most countries around the world including Finland, China, Sweden, Germany, Netherlands. Some countries end up having two national standards such as Norway. I will discuss the specific situations with Chinese and Arabic each in future articles.
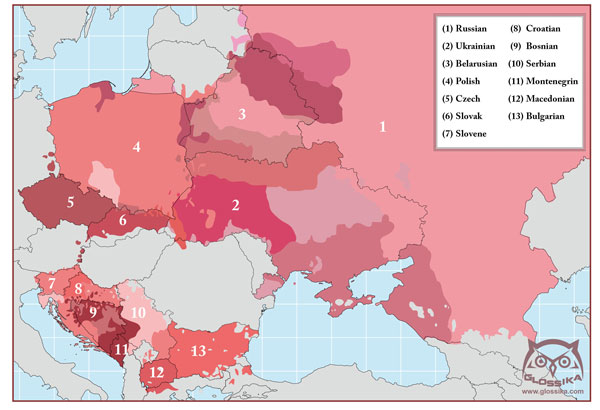
Before 1000 CE, most of the Slavs spoke almost the same language, but as their territory spread, more languages developed over time. Today Slovak and Czech are approximately 1000 years old and are at the temporal barrier of no longer being intelligible. Now that each have their own national standards, the languages have definitely crossed that threshold and will continue changing in their own directions.
Proto-languages
With all of the information we have about how languages have changed, linguists are able to reconstruct proto-languages with a high level of accuracy. Not only the sounds but also the grammar and structure of the languages.
The languages descended from Latin are called Romance languages, and essentially they are variations of Latin and of each other. If you know one of these languages, once you identify what the variations are, the other languages are not just easier to understand but also easier to learn to speak.
The Germanic and Celtic languages to the north have a deeper level of variation from Romance. If you want to see the sound correspondences between these groups, you have to compare their protolanguages. The variation you find between protolanguages is also very similar to the variation you find between the languages within a group.
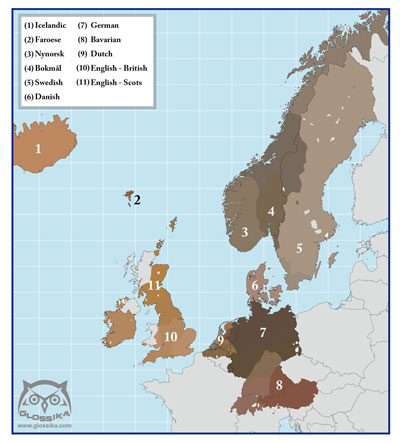
The languages of Europe all fall within several related groups: Celtic, Germanic, Romance/Italic, Slavic, Baltic, although Greek and Albanian are isolates. If this is new to you, there are two things I'd like to share with you that might surprise you. First, the languages from Bangladesh (Bengali) to Turkey (Kurdish) are also related, belonging to the Indo-Iranian group. This is why the family as a whole is called the Indo-European family.
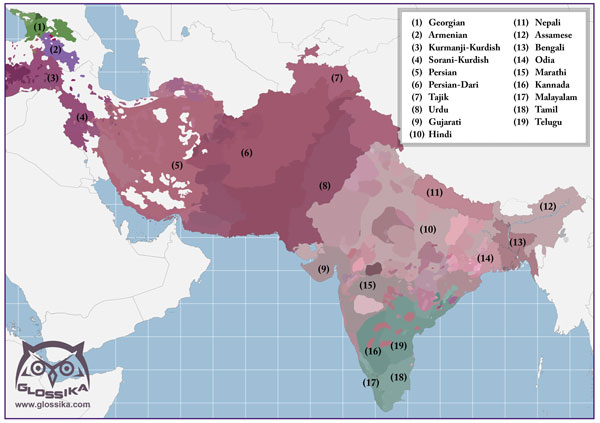
Persian, the national language of Iran is a major language in the family and belongs to the Indo-Iranian branch. When I started learning it some of the verbs reminded me of German, and at other times, it reminded me of Italian. Both German and Italian helped me remember and encode aspects of the grammar the first time I encountered it. While learning Hindi I used sound correspondences I knew in Slavic languages to help me remember vocabulary. In fact I use sound correspondences to remember vocabulary as much as possible.
The second thing that might surprise you about European languages is that some of them don't belong to the Indo-European family at all. A lot of people don't realize this and simply label them as some of the most difficult languages to learn but this is not entirely true because in some cases the grammars and sounds are not as complex. Basque has been spoken in northern Spain since before the Romans arrived. It is the only surviving pre-European language and deserves its title of being a notoriously difficult language. The others (Finnish, Estonian, Hungarian) belong to the Uralic family and are not as complex as the Indo-European languages. The difficulty of them lies in the fact that they are just completely different both lexically and grammatically.
The larger the difference between two languages, the harder they appear to learn even if they are not complex grammatically or phonologically.
The date of IE and its protolanguage.
If we know that typically existing languages are at least a thousand years old, and the languages they descended from are more than 2000 years old, to go back further to find the mother language family takes a lot of research and testing of theories. Linguists develop rules to describe the changes and make sure the rules are functioning in all the languages. It's like writing a computer program that generates the modern languages based on the protolanguage. If the protolanguage is reconstructed correctly and the rules work then the resulting languages can be generated.
What's interesting about this is that if we familiarize ourselves with a few of these rules that apply to Germanic or Slavic, it's possible to start recognizing large amounts of vocabulary. This allows you to jump into the language and start practicing sentences because the vocabulary feels familiar.
Although many languages share vocabulary known as cognates, the actual words are used differently in different languages. There are many examples of such false friends otherwise known as faux amis.
Even though one cognate might be in widespread use throughout Europe, some languages may use a different root. For example, most languages in Europe have 'kaput' as a cognate for 'head' (in fact, if you don't recognize the parts, 'head' is actually a direct descendant of 'kaput' and I'll show you why in the next article titled Hacking Vocabulary with the DNA of Language). However both standard Italian and French use 'testa' instead. You need to apply the fricative loss rule to Modern French by deleting the <s> and adding a circumflex lengthener over the vowel (or into <é> at the beginning of a word) to generate 'tête'.
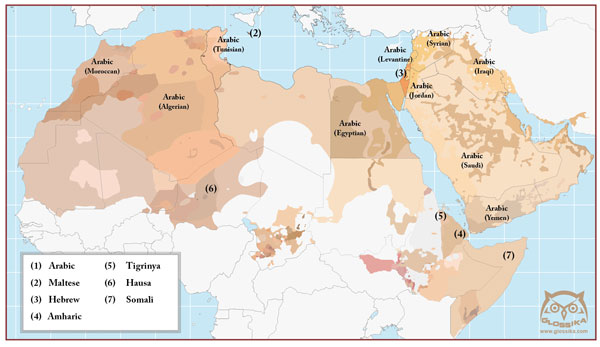
The world is a big place and so far we've only touched on the Indo-European family and briefly mentioned the Uralic family. We'll take a look at the Afroasiatic family in a future article and how the vocabulary is made up of consonantal roots. In fact, I usually use the same technique for identifying words in Indo-European as well and find it's very useful once you understand sound patterns.
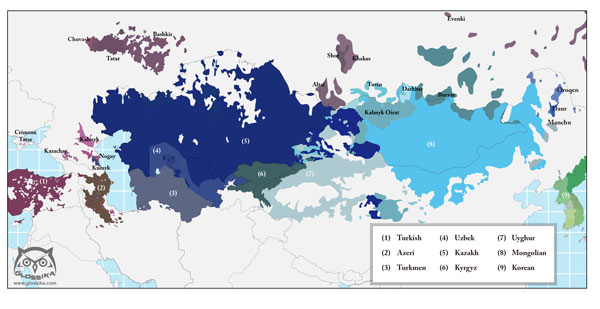
The Altaic language family extends from Turkey in a band all the way across Asia to the far east. It cannot be proven linguistically that Korean and Japanese belong to Altaic, but as a language learner, there are too many things in common enabling us to use the connections as mnemonic devices. So it's a good idea to think of Japanese and Korean as structurally Altaic.
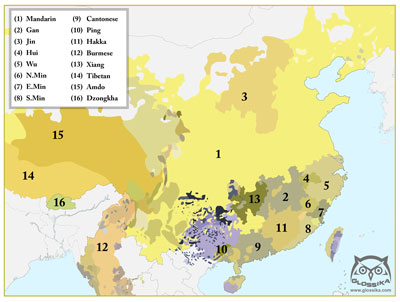
The Sino-Tibetan family in east Asia includes Chinese, Tibetan, Burmese and many smaller languages. It does not include Japanese or Korean or Vietnamese, but have given all three languages are large amount of vocabulary. The structure of Japanese and Korean are so different from Chinese, that most people never master each other's languages.
Sound Changes
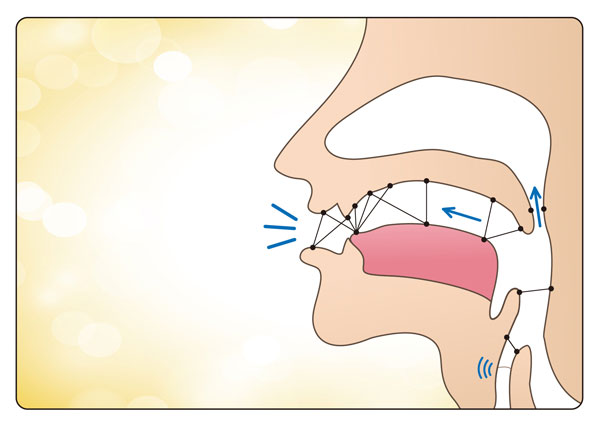
The next important thing we need to learn about are sound changes. Familiarize yourself with the following points because we'll start applying these in the next article. The examples below make use of approximate English spellings (especially the palatals) rather than the more correct IPA phonemes. This is to help people who are new to linguistics grasp the major concepts easily. Capital letters are used to express a class of sounds.
- The major points of articulation in the mouth:
- /P/: lips, a phonestheme characteristic of fat, round, bubbly, bulbous, popping, exploding things.
- /T/: the alveolar ridge behind the teeth, a phonestheme characteristic of thin, dull, blunt, long, flat things.
- /C/: using the flat part of the tongue against the roof of the mouth which is called the palate, a phonestheme characteristic of sticking out or connecting things.
- /K/: using the back of the tongue, a phonestheme characteristic of sharp things.
- Change stops into flowing sounds: P>f, T>s, C>sh, K>x
- Change stops into voiced sounds: P>b, T>d, C>j, K>g
- Change stops into nasal sounds (N): P>m, T>n, C>ny, K>ng
- Change flowing into voiced sounds: f>v, s>z, sh>zh, K>gh
- Combine stops and flowing sounds: pf, ts, ch, kx
- And voice those stop-flowing sounds: bv, dz, dj, gh
- Change them into liquids and semi-vowels: W, R and L, LY and Y
- There are many things we can do, like lightly tapping all of these positions, adding a puff of air at different degrees, devoicing the nasals, articulating sounds halfway between the four main points, and making use of the uvula and throat space for even more sounds. Check out our upcoming series of phonics videos to learn all about producing these sounds.
In the next post, just keep in mind the relationships of these sounds in the mouth so that we can talk about how they interact with each other as words get spread throughout hundreds of languages within a language family. I'll show you how to use these ideas to hack and learn massive amounts of vocabulary across an entire language family, and even how to build up memory trees of vocabulary in other language families.
Join us and Make an Impact!
We are on a big mission to bring access to any language and would like to invite you to join us!
Support our mission: viva.glossika.com.

